神经网络中行归一化与正交化的渐近等价性
TL;DR. 在神经网络中,正交化与沿输入维度的逐行 $\ell_2$ 归一化这两类看似不同的矩阵级预条件方法,实际上是渐近等价的。本文从理论和实验两方面支持这一结论。理论上,我们在初始化处对三个传统神经网络理论模型中的梯度自外积进行了闭式分析:矩阵分解、深线性网络和两层 ReLU 网络;结果表明,在这些模型中,行归一化与正交化渐近等价。经验上,我们跟踪了不同尺度 GPT-2 和 LLaMA 的完整训练动态,并验证了在整个训练动态过程中,正交化与行归一化始终保持近似等价。结合以上两方面的分析,一个长期存在的问题也得到了解释:为什么基于正交化的预条件方法能够如此自然地适配神经网络的曲率结构? 答案在于,它的作用方向隐式对齐了神经网络块对角占优的 Hessian 结构。
1. Muon
Muon [1] 是一个面向矩阵参数 $W_t \in \mathbb{R}^{m \times n}$ 的动量型优化器。记第 $t$ 步的随机梯度为 $G_t = \nabla f(W_t; \xi^t)$,它的更新过程可以写成
\[\begin{aligned} G_t &= \nabla f(W_t; \xi^t), \\ V_t &= \beta V_{t-1} + (1 - \beta) G_t, \\ D_t &= \mathrm{NS}_5(V_t) \approx (V_t V_t^\top)^{-1/2} V_t, \\ W_{t+1} &= W_t - \eta_t D_t, \end{aligned}\]其中 $V_0 = 0$,$\beta \in [0,1)$ 为动量系数,$\eta_t > 0$ 为学习率。Muon 的关键之处在于下降方向 $D_t$:它并不直接使用动量 $V_t$,而是先对其做一次正交化。如果用 SVD 来实现这一步,那么有
\[D_t \;=\; U V^\top \;=\; (V_t V_t^\top)^{-1/2} \, V_t.\]2. Muon 为什么能适配神经网络的 Hessian 结构
Muon 为什么能够自然地适配神经网络的 Hessian 结构?这正是本文想回答的核心问题。传统优化理论(主要指非凸光滑假设下的最速下降框架)已经发展了很长时间,但像 Muon 这样结构简单的预条件方法,为什么直到最近才被发现能在神经网络训练中显著优于许多常见优化器? 这种优势,难以被这套传统理论充分解释。这一缺口并非偶然。传统理论通常关注某个抽象问题类中的最坏情形,因此很难刻画真实神经网络问题里那些真正主导训练行为的结构性特征。要理解 Muon 为什么有效,我们就必须回到神经网络本身的结构上来。
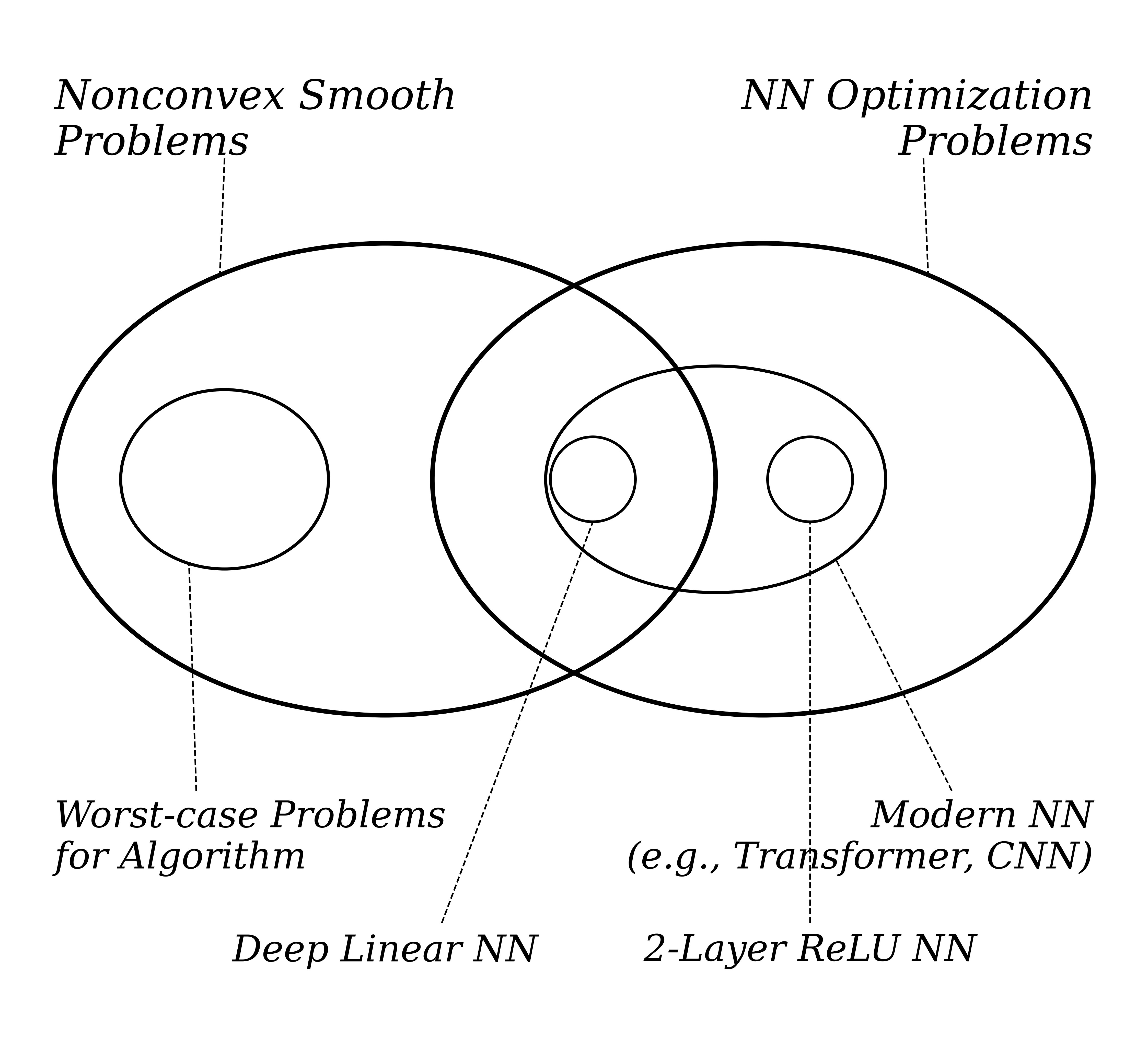
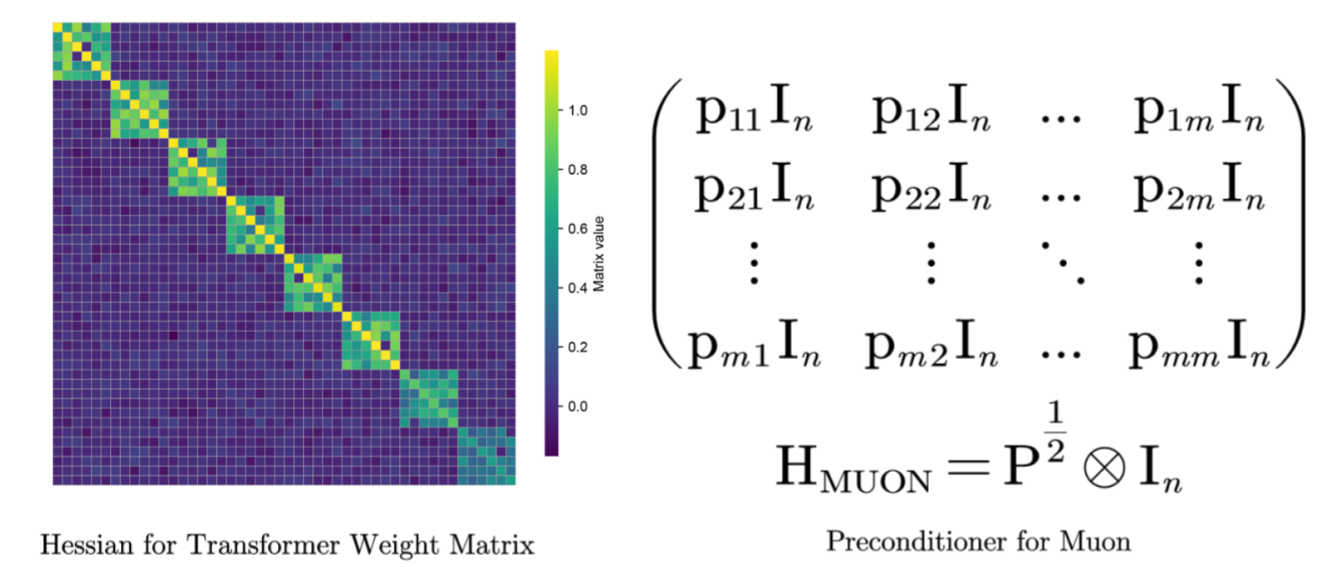
[2,3,4] 的一系列经验与理论工作表明:神经网络逐层的 Hessian 往往呈现出按行分块的对角占优结构。更具体地说,当我们把权重矩阵 $W \in \mathbb{R}^{m \times n}$ 的 Hessian 沿着 $m$ 个行方向拆成大小为 $n \times n$ 的子块时,对角块通常在量级上主导非对角块。
由于在损失函数的二次近似下,Hessian 就是最优预条件器,因此这种按行分块的结构实际上告诉我们:一个“好”的预条件器应该长什么样。
如果把 Muon 在参数空间中的隐式预条件器 $H$ 写成 Kronecker 乘积的形式,就可以得到
\[H_{\mathrm{MUON}} \;=\; P_t^{1/2} \otimes I_n, \qquad P_t \;:=\; V_t V_t^\top.\]因此,Muon 预条件器的结构完全由 $V_t V_t^\top$ 的结构决定。和 Hessian 的图景对照起来看,就会发现:如果 $V_t V_t^\top$ 是对角的,那么 $H_{\mathrm{MUON}} = P_t^{1/2} \otimes I_n$ 就会恰好具有与 Hessian 一致的按行分块对角结构。
于是,自然会引出下面这个结构性问题:
对神经网络而言,$V_t V_t^\top$(等价地,$G_t G_t^\top$)是否是对角占优的?
对于神经网络的权重矩阵来说,在宽度趋于无穷的渐近极限下,答案是肯定的。
这篇博客给出了一些初步理论结果。在三个传统神经网络理论模型中,矩阵分解、深线性网络和两层 ReLU 网络,我们在初始化处的分析都指向同一个结论。而对于真实模型在完整训练过程中的经验证据,可以参见我们的论文 [5],其中包含 GPT-2 与 LLaMA 的完整动态分析。
图 2 概括了这种结构对应关系:当 $V_t V_t^\top$ 接近对角矩阵时,Muon 的预条件器就会沿着行分块方向自然对齐,而这恰好匹配了神经网络 Hessian 中占主导地位的行分块结构。
3. 神经网络Setup下的理论理解
如果你不想看具体的数学理论,可以直接跳到第 4 节,看实践中的经验证据。
下面我们从理论上解释这一现象。具体来说,我们分析了三个传统神经网络理论模型在初始化处的梯度自外积的渐近结构。由于每个模型的推导都比较长,这里只展示两层 ReLU 神经网络的结果,用它来传达核心图景;完整证明可以在对应的 proof notes 中找到。
| 模型 | 设定 | 证明笔记 |
|---|---|---|
| 矩阵分解 | \(\mathcal{L}(U) := \tfrac{1}{4} \| U U^\top - M^\star \|_F^2,\ U \in \mathbb{R}^{d \times k}\) | note |
| 深线性网络 | \(\mathcal{L}(W_1, \ldots, W_L) := \tfrac{1}{2} \mathbb{E}_x \| W_L \cdots W_1 x - \Phi x \|^2\) | note |
| 两层 ReLU | \(\mathcal{L}(W_1, W_2) := \tfrac{1}{2} \mathbb{E}_x \| W_2 \sigma(W_1 x) - \Phi x \|^2\) | note |
3.1 设定
记 $d_0$ 为输入维度,$d_1$ 为隐藏层宽度,这也是本文关心的渐近方向,$d_2$ 为输出维度。考虑如下两层 ReLU 网络:
\[f(x) \;=\; W_2 \, \sigma(W_1 x), \qquad W_1 \in \mathbb{R}^{d_1 \times d_0}, \quad W_2 \in \mathbb{R}^{d_2 \times d_1},\]其中 $\sigma(z) := \max(z, 0)$,输入满足 $x \in \mathbb{R}^{d_0}$。记 $h(x) := \sigma(W_1 x) \in \mathbb{R}^{d_1}$,并用 $w_a \in \mathbb{R}^{d_0}$ 表示 $W_1$ 的第 $a$ 行。针对确定性线性目标 $\Phi \in \mathbb{R}^{d_2 \times d_0}$,总体损失定义为
\[\mathcal{L}(W_1, W_2) \;:=\; \tfrac{1}{2}\, \mathbb{E}_x \| W_2\, \sigma(W_1 x) - \Phi x \|^2,\]记 $G_{i,t} := \partial \mathcal{L} / \partial W_i$。在 $t = 0$ 时,动量恰好等于梯度,因此 $V_0 = G_0$,从而有 $V_t V_t^\top = G_t G_t^\top$。
基本假设。 在初始化时,
\[(W_1)_{ij}, (W_2)_{ij} \stackrel{\mathrm{iid}}{\sim} \mathcal{N}(0,1), \qquad x \sim \mathcal{N}(0, I_{d_0}),\]并且 $\Phi$ 是确定的,且与 $W_1, W_2$ 相互独立。
3.2 梯度自外积的闭式结构
定理 1($\mathbb{E}[G_{2,t} G_{2,t}^\top]$ 的结构).
\[\mathbb{E}[G_{2,t} G_{2,t}^\top] \;=\; \alpha\, I_{d_2} \; + \; \frac{d_1}{4}\, \Phi \Phi^\top,\]其中 $\alpha := \mathbb{E}_{W_1}[\mathrm{tr}(H^2)]$,$H := \mathbb{E}_x[h(x) h(x)^\top]$,并且当 $d_0, d_1 \to \infty$ 时,$\alpha = \Theta(d_0^2 d_1^2)$。
定理 2($\mathbb{E}[G_{1,t} G_{1,t}^\top]$ 的结构). $\mathbb{E}[G_{1,t} G_{1,t}^\top]$ 对隐藏层索引具有置换不变性。其中对角项为
\[\mathbb{E}[(G_{1,t} G_{1,t}^\top)_{aa}] \;=\; \frac{d_0 d_2^2}{4} \; + \; d_0 d_2\!\left[(d_1 - 1)\kappa_1 + \tfrac{1}{2}\right] \; + \; \frac{\|\Phi\|_F^2}{4},\]而当 $a \neq c$ 时,
\[\mathbb{E}[(G_{1,t} G_{1,t}^\top)_{ac}] \;=\; d_0 d_2\, \kappa_2 \; + \; O(d_2 \sqrt{d_0}),\]其中 $\kappa_1, \kappa_2$ 是与维度无关的常数,它们由两个独立标准高斯之间的夹角分布给出。当 $d_0 \to \infty$ 时,有 $\kappa_1 \to 1/(4\pi^2) + 1/16$,$\kappa_2 \to 1/(4\pi)$。
3.3 对角占优的渐近结论
根据定理 1 和定理 2,可以把主导阶总结如下:
| 对角项 | 非对角项 | |
|---|---|---|
| \(\mathbb{E}[G_{2,t} G_{2,t}^\top]\) | \(\Theta(d_0^2 d_1^2) + \tfrac{d_1}{4}(\Phi \Phi^\top)_{aa}\) | \(\tfrac{d_1}{4}(\Phi \Phi^\top)_{ac}\) |
| \(\mathbb{E}[G_{1,t} G_{1,t}^\top]\) | \(\Theta(d_0 d_2^2 + d_0 d_1 d_2)\) | \(\Theta(d_0 d_2)\) |
我们关心的渐近区域是:让隐藏宽度 $d_1 \to \infty$,同时保持输入维度 $d_0$ 与输出维度 $d_2$ 固定。沿着 $d_1$ 这一方向读取上表,可以看到:$\mathbb{E}[G_{1,t} G_{1,t}^\top]$ 的对角项按 $\Theta(d_1)$ 增长,而非对角项保持在 $\Theta(1)$。因此,对角占优比率满足
\[\frac{\mathbb{E}[(G_{1,t} G_{1,t}^\top)_{aa}]}{\mathbb{E}[(G_{1,t} G_{1,t}^\top)_{ac}]} \;=\; \Theta(d_1).\]特别地,当隐藏宽度 $d_1 \to \infty$ 时,$G_{1,t} G_{1,t}^\top$ 会渐近地变成对角矩阵:对角项相对于非对角项的优势因子会线性增长。
这一机制其实并不难理解。高维空间中的独立高斯向量在期望意义下近似正交,这对应了非对角项的表现;而高斯向量与自身内积的期望会随着维数增长,这对应了对角项的表现。在这里,神经网络的隐藏宽度就扮演了这种“维数”的角色:初始化时各行向量的高度独立性,在梯度层面也会保留出类似的近正交结构。因此,随着隐藏宽度增大,非对角项增长更慢,而对角项增长更快,$G_{1,t} G_{1,t}^\top$ 便会渐近呈现对角占优。
这个 0-step 结果,是该现象在最简单模型中的一次解析呈现。下一节会看到:在真实训练过程中,同样的结构力量依然存在。
4. 全训练动态中的经验现象
为了检验这一现象在真实模型中是否依然成立,我们在论文 [5] 中对 GPT-2 和 LLaMA 的完整训练过程进行了实验验证。结果表明,$V_t V_t^\top$ 不仅在 Toy Model 之外仍然保持对角占优,而且这种结构还会在训练过程中持续显现。具体来说,我们对训练全过程里的每一个矩阵参数都跟踪了如下按行占优比率:
\[r_i \;:=\; \frac{(V_t V_t^\top)_{ii}}{\frac{1}{m-1}\sum_{j \neq i} |(V_t V_t^\top)_{ij}|},\]然后把这些比率汇总成每层的最小值、平均值和最大值,分别记为 $r_{\min}, r_{\mathrm{avg}}, r_{\max}$;再在网络的所有矩阵参数之间做平均,得到 $\bar r_{\min}, \bar r_{\mathrm{avg}}, \bar r_{\max}$。
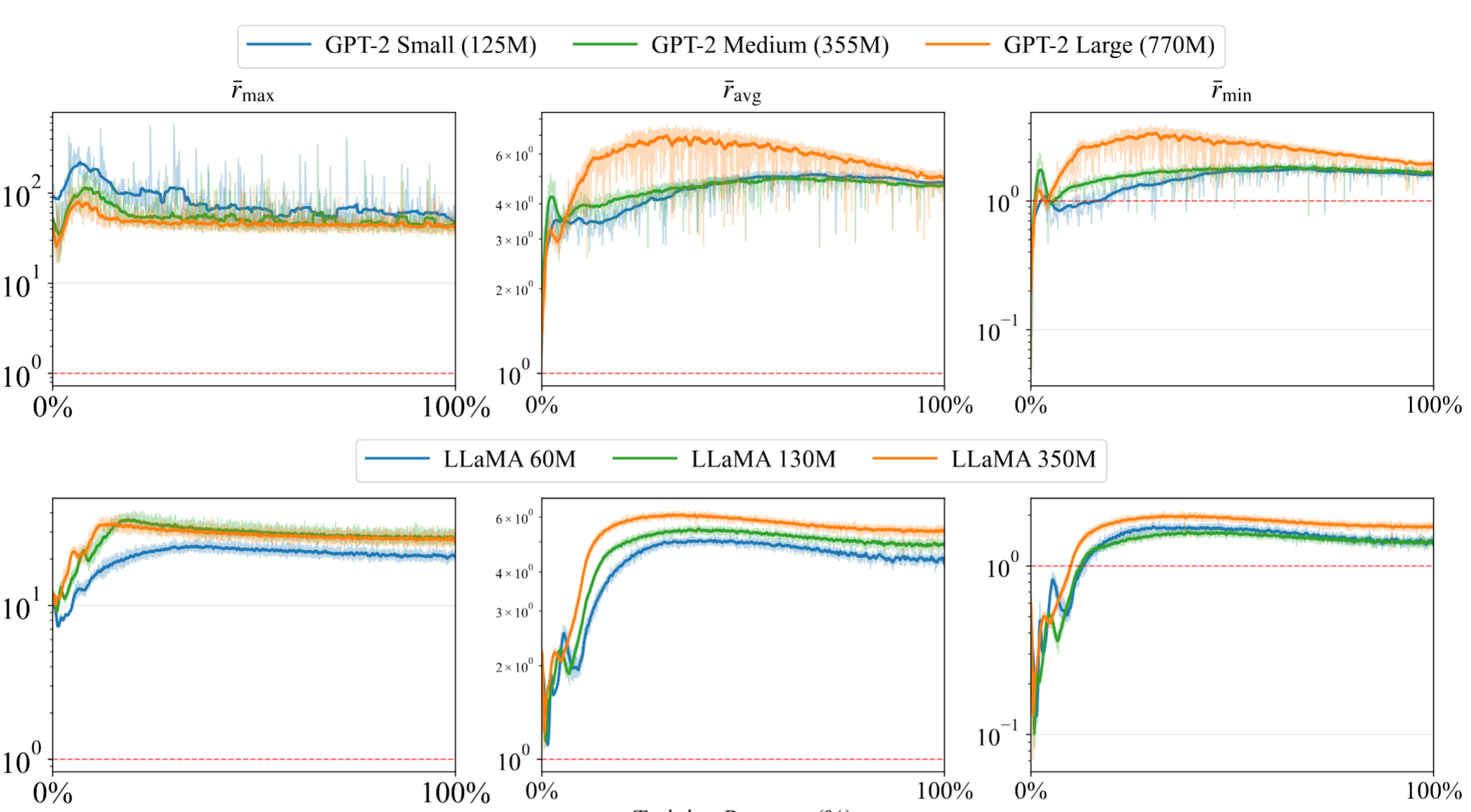
这里有三个经验现象尤其值得强调:
- 这些比率会在训练早期越过 $1$,并稳定保持在其上。 在 warm-up 结束后,$\bar r_{\min}, \bar r_{\mathrm{avg}}, \bar r_{\max}$ 都会在训练最初的若干百分比内升到 $1$ 以上,并在后续阶段持续保持这一状态。
- 对角占优会随着模型规模增大而增强。 无论是 GPT-2 还是 LLaMA,较大模型的 $\bar r_{\mathrm{avg}}$ 与 $\bar r_{\min}$ 都明显更高,这和定理 2 预测的 $\Theta(d_1)$ 渐近标度是一致的。
- 这一现象并不依赖于特定架构。 GPT-2 与 LLaMA 都呈现出相同的定性行为,这说明对角占优更像是良态 Transformer 训练中的普遍性质,而不是某种具体结构设计的偶然产物。
简言之,在不同模型家族、不同模型规模以及完整训练过程中,$V_t V_t^\top$ 不仅呈现出对角占优,而且随着模型规模增大,这种占优还会进一步增强。
5. RMNP:Muon 的高效替代物
现在我们可以把前面的图景闭合起来。回忆 Muon 的更新方向:
\[D_t^{\text{Muon}} \;=\; (V_t V_t^\top)^{-1/2}\, V_t.\]假设 $V_t V_t^\top$ 是对角矩阵,那么显然有 $V_t V_t^\top = \mathrm{diag}(V_t V_t^\top)$,因此
\[(V_t V_t^\top)^{-1/2} \;=\; \mathrm{diag}(V_t V_t^\top)^{-1/2}.\]右边是一个逐行作用的算子。记 $V_{t,i:}$ 为 $V_t$ 的第 $i$ 行,则 $\mathrm{diag}(V_t V_t^\top){ii} = |V{t,i:}|_2^2$,并且
\[\bigl[ \mathrm{diag}(V_t V_t^\top)^{-1/2}\, V_t \bigr]_{i,:} \;=\; \frac{V_{t,i:}}{\|V_{t,i:}\|_2}.\]也就是说,当 $V_t V_t^\top$ 为对角矩阵时,应用 $(V_t V_t^\top)^{-1/2}$ 与沿输入维度做 $\ell_2$ 逐行归一化完全等价。 换句话说,$V_t$ 的每一行,作为输入轴上的一个向量,都会被自己的 $\ell_2$ 范数单独归一化。类似的操作最早在 [6] 中从 norm-constrained steepest descent 的角度进行过讨论。
基于这一观察,我们提出了 RMNP(Row-Momentum Normalized Preconditioning):它用这种沿输入维度的归一化,来替代 Muon 中代价更高的正交化步骤:
\[D_t^{\text{RMNP}} \;:=\; \mathrm{diag}(V_t V_t^\top)^{-1/2}\, V_t.\]等价地,RMNP 的隐式预条件器与 Muon 具有相同的 Kronecker 形式,但只保留了 $P_t = V_t V_t^\top$ 的对角块:
\[H_{\mathrm{RMNP}} \;=\; \mathrm{diag}(P_t)^{1/2} \otimes I_n.\]
结合前两节中的对角占优结果,我们得到一个非常清晰的图景:当模型宽度趋于无穷时,RMNP 与 Muon 是渐近等价的。 Muon 中代价为 $\Theta(mn \min(m,n))$ 的正交化步骤,会退化为一个简单的 $\Theta(mn)$ 输入维度 $\ell_2$ 归一化,而不会损失对神经网络的预条件质量。
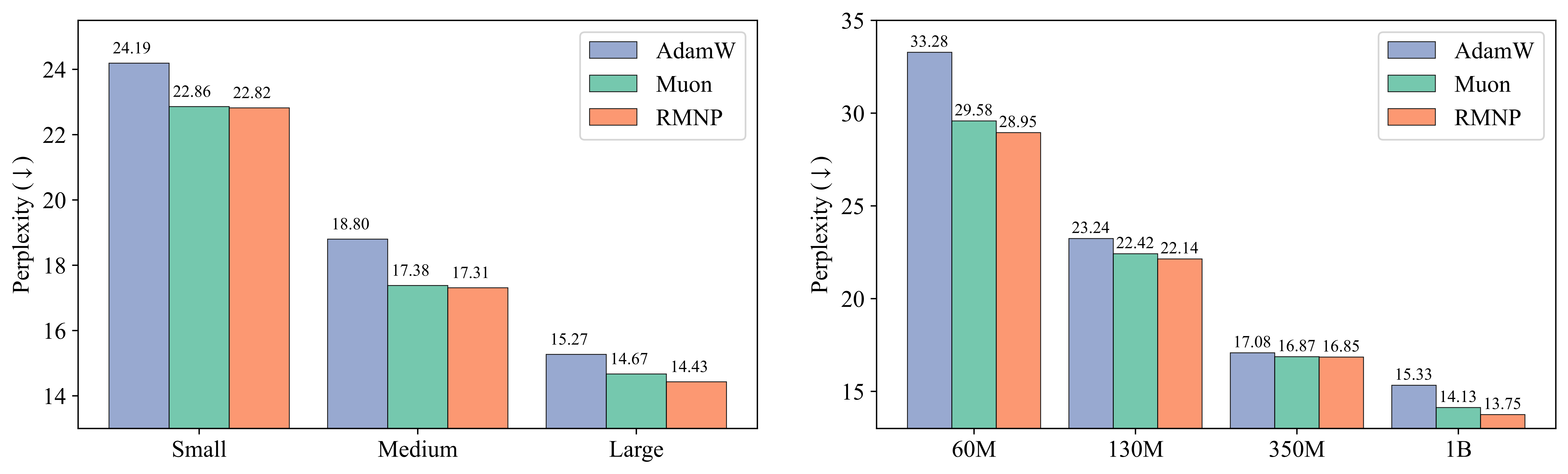
我们的论文 [5] 表明在 GPT-2(125M 到 1.5B)和 LLaMA(60M 到 1B)上对每个优化器都进行多轮超参数搜索之后 RMNP 相对 Muon 提供了 comparable preformance表现。
若想了解更多关于行归一化、列归一化,以及归一化型优化器其他优势的经验结果,也可以参考以下同期工作:
- [7] A Minimalist Optimizer Design for LLM Pretraining.
- [8] SRON: State-Free LLM Training via Row-Wise Gradient Normalization.
- [9] Mano: Restriking Manifold Optimization for LLM Training.
- [10] On the Width Scaling of Neural Optimizers Under Matrix Operator Norms I: Row/Column Normalization and Hyperparameter Transfer.
- [13] Aurora: A Leverage-Aware Optimizer for Rectangular Matrices.
以及更早一些关于不同归一化方案的经验探索:
- [11] Gradient Multi-Normalization for Stateless and Scalable LLM Training.
- [12] SWAN: SGD with Normalization and Whitening Enables Stateless LLM Training.
- [6] Training Deep Learning Models with Norm-Constrained LMOs.
6. 参考文献
[1] Keller Jordan, Yuchen Jin, Vlado Boza, Jiacheng You, Franz Cesista, Laker Newhouse, and Jeremy Bernstein. Muon: An optimizer for hidden layers in neural networks. 2024. https://kellerjordan.github.io/posts/muon/
[2] Yushun Zhang, Congliang Chen, Tian Ding, Ziniu Li, Ruoyu Sun, and Zhi-Quan Luo. Why Transformers Need Adam: A Hessian Perspective. In Advances in Neural Information Processing Systems (NeurIPS), 2024. arXiv:2402.16788. https://arxiv.org/abs/2402.16788
[3] Yushun Zhang, Congliang Chen, Ziniu Li, Tian Ding, Chenwei Wu, Diederik P. Kingma, Yinyu Ye, Zhi-Quan Luo, and Ruoyu Sun. Adam-mini: Use Fewer Learning Rates To Gain More. arXiv preprint arXiv:2406.16793, 2024. https://arxiv.org/abs/2406.16793
[4] Zhaorui Dong, Yushun Zhang, Jianfeng Yao, and Ruoyu Sun. Towards Quantifying the Hessian Structure of Neural Networks. arXiv preprint arXiv:2505.02809, 2025. https://arxiv.org/abs/2505.02809
[5] Shenyang Deng, Zhuoli Ouyang, Tianyu Pang, Zihang Liu, Ruochen Jin, Shuhua Yu, and Yaoqing Yang. RMNP: Row-Momentum Normalized Preconditioning for Scalable Matrix-Based Optimization. In Proceedings of the 43rd International Conference on Machine Learning (ICML), 2026.
[6] Thomas Pethick, Wanyun Xie, Kimon Antonakopoulos, Zhenyu Zhu, Antonio Silveti-Falls, and Volkan Cevher. Training Deep Learning Models with Norm-Constrained LMOs. In Proceedings of the 42nd International Conference on Machine Learning (ICML), 2025. https://arxiv.org/abs/2502.07529
[7] Athanasios Glentis, Jiaxiang Li, Andi Han, and Mingyi Hong. A Minimalist Optimizer Design for LLM Pretraining. arXiv preprint arXiv:2506.16659, 2025. https://arxiv.org/abs/2506.16659
[8] Ziqing Wen, Yanqi Shi, Jiahuan Wang, Ping Luo, Linbo Qiao, Dongsheng Li, and Tao Sun. SRON: State-Free LLM Training via Row-Wise Gradient Normalization. OpenReview, 2025. https://openreview.net/forum?id=BtQLBWr6zI
[9] Yufei Gu and Zeke Xie. Mano: Restriking Manifold Optimization for LLM Training. arXiv preprint arXiv:2601.23000, 2026. https://arxiv.org/abs/2601.23000
[10] Ruihan Xu, Jiajin Li, and Yiping Lu. On the Width Scaling of Neural Optimizers Under Matrix Operator Norms I: Row/Column Normalization and Hyperparameter Transfer. arXiv preprint arXiv:2603.09952, 2026. https://arxiv.org/abs/2603.09952
[11] Meyer Scetbon, Chao Ma, Wenbo Gong, and Edward Meeds. Gradient Multi-Normalization for Stateless and Scalable LLM Training. arXiv preprint arXiv:2502.06742, 2025. https://arxiv.org/abs/2502.06742
[12] Chao Ma, Wenbo Gong, Meyer Scetbon, and Edward Meeds. SWAN: SGD with Normalization and Whitening Enables Stateless LLM Training. In Proceedings of the 42nd International Conference on Machine Learning (ICML), 2025. arXiv:2412.13148. https://arxiv.org/abs/2412.13148
[13] Alec Dewulf, Dhruv Pai, Li Yang, Ashley Zhang, and Ben Keigwin. Aurora: A Leverage-Aware Optimizer for Rectangular Matrices. Tilde Research Blog, 2026. https://blog.tilderesearch.com/blog/aurora
7. 如何引用这篇博客
Cite. 如果这篇文章对你有帮助,可以按如下方式引用:
@misc{rmnp_blog_2026,
title = {Row Normalization and Orthogonalization Are Asymptotically Equivalent on Neural Networks},
author = {Shenyang Deng},
year = {2026},
note = {Blog post},
url = {https://dsyforever.github.io/blog/normalization-orthogonalization/}
}8. 致谢
感谢 Yushun Zhang、Shuhua Yu 和 Yaoqing Yang 提供的讨论与反馈。后续如有需要,这份名单还会继续补充。